Overview
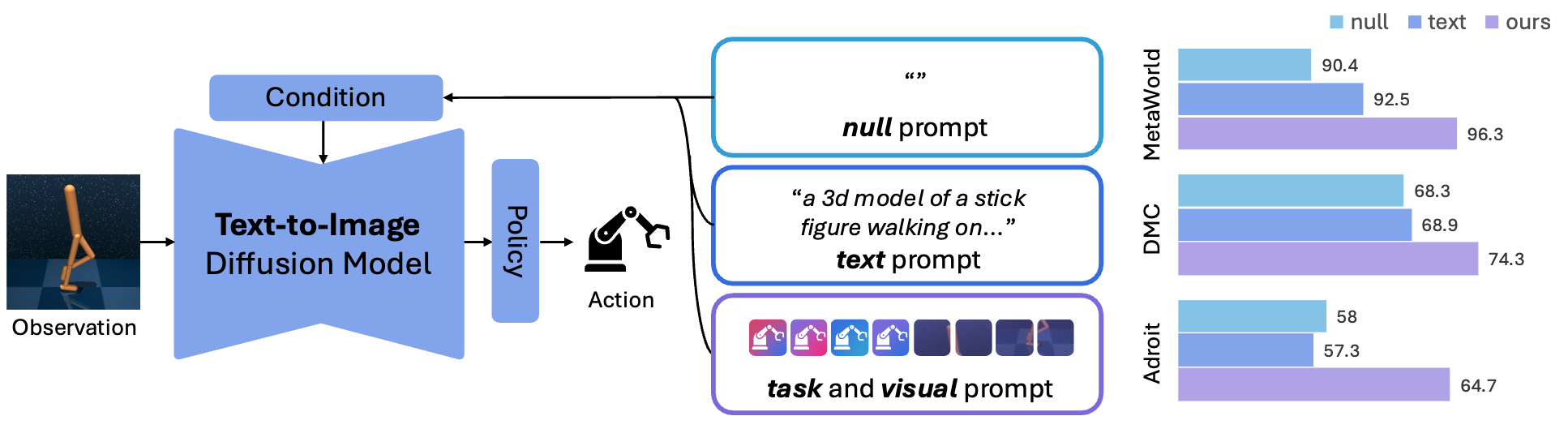
Motivation
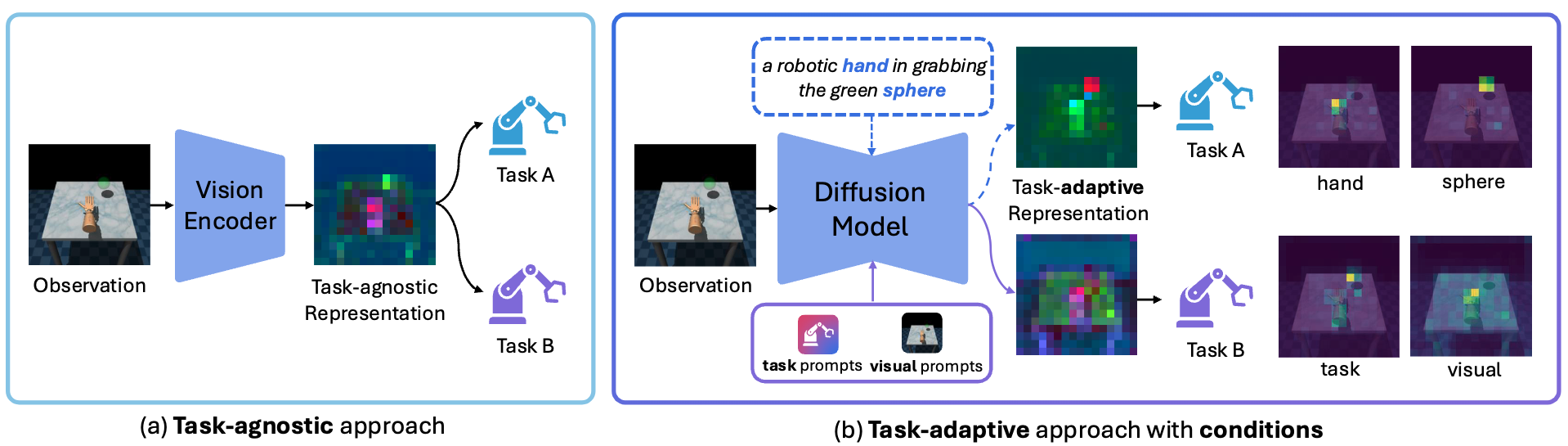
Conditional diffusion models, such as Stable Diffusion, are capable of genereting visual representation with regard to the given condition. Can we leverage such capability of diffusion models for robotic control tasks to overcome the previous limitations of task-agnostic representations in previous approaches and achieve better performance in various control tasks in a task-adaptive manner?
Exploring textual conditions for robotic control
Text conditions, such as image captions or task descriptions, were shown to be effective in various downstream visual tasks. However, we find that the same does not apply for robotic control tasks. We hypothesize that this is due to the noisy grounding in cross-attention maps, originating from the domain gap between real-world images that diffusion models were trained on and the simulated robotic environments. Moreover, text conditions fall short in providing detailed information about the current scene as it neglects the visual information, which is crucial for robotic control.
Methodology
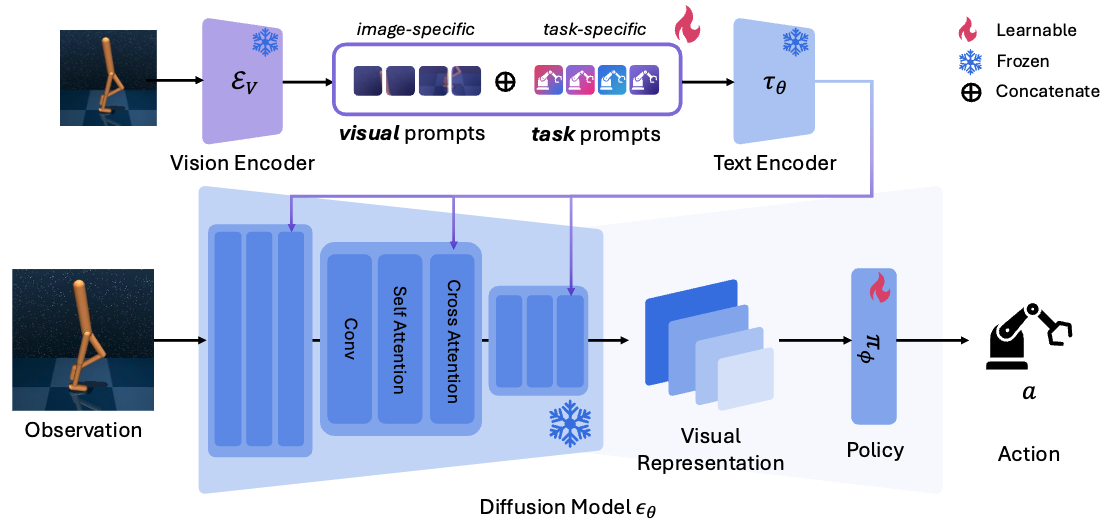
Task prompts are shared across scenes in a single task, and aims to act as an implicit description for representing the task and the environment context.
Visual Prompts aim to capture dynamic frame-specific details for accurate control through leveraging dense representations from a pre-trained visual encoder.
We design our conditions to adapt to the control environment, preventing erroneous grounding, while simultaneously incorporating visual information to capture dynamic details. To achieve this with minimal overhead, we formulate these conditions as learnable prompts, which can be optimized during downstream policy learning.
Results
DeepMind Control
| Methods | Backbone | Walker-stand | Walker-walk | Reacher-easy | Cheetah-run | Finger-spin | Mean |
|---|---|---|---|---|---|---|---|
| CLIP | ViT-L/16 | 87.3 ± 2.4 | 58.3 ± 4.4 | 54.5 ± 4.6 | 29.9 ± 5.6 | 67.5 ± 2.1 | 59.5 |
| VC-1 | ViT-L/16 | 86.1 ± 0.9 | 54.3 ± 6.6 | 18.3 ± 2.4 | 40.9 ± 2.7 | 65.7 ± 1.1 | 53.1 |
| SCR | SD 1.5 | 85.5 ± 2.6 | 64.3 ± 3.5 | 81.8 ± 9.9 | 43.4 ± 6.4 | 66.6 ± 2.7 | 68.3 |
| Text (Simple) | SD 1.5 | 87.6 ± 4.6 | 67.9 ± 4.6 | 84.3 ± 4.6 | 38.8 ± 5.9 | 66.7 ± 0.2 | 69.1 |
| Text (Caption) | SD 1.5 | 87.2 ± 4.5 | 68.3 ± 5.9 | 86.2 ± 1.9 | 37.5 ± 2.6 | 65.1 ± 1.8 | 68.9 |
| CoOp | SD 1.5 | 87.2 ± 2.2 | 67.8 ± 6.4 | 87.1 ± 5.9 | 45.0 ± 6.4 | 65.9 ± 1.0 | 70.6 |
| TADP | SD 1.5 | 89.0 ± 2.9 | 69.9 ± 7.9 | 86.6 ± 5.6 | 41.1 ± 3.9 | 66.9 ± 0.2 | 70.7 |
| ORCA (Ours) | SD 1.5 | 89.1 ± 1.8 | 76.9 ± 4.0 | 87.6 ± 2.9 | 50.0 ± 8.4 | 68.0 ± 1.0 | 74.3 |
MetaWorld
| Methods | Backbone | Assembly | Bin-picking | Button-press | Drawer-open | Hammer | Mean |
|---|---|---|---|---|---|---|---|
| CLIP | ViT-L/16 | 85.3 ± 12.2 | 69.3 ± 8.3 | 60.0 ± 13.9 | 100.0 ± 0.0 | 92.0 ± 8.0 | 81.3 |
| VC-1 | ViT-L/16 | 93.3 ± 6.1 | 61.3 ± 12.2 | 73.3 ± 8.3 | 100.0 ± 0.0 | 93.3 ± 6.1 | 84.2 |
| SCR | SD 1.5 | 92.0 ± 6.9 | 86.7 ± 4.6 | 74.7 ± 12.9 | 100.0 ± 0.0 | 98.7 ± 2.3 | 90.4 |
| Text (Simple) | SD 1.5 | 97.3 ± 2.3 | 85.3 ± 2.3 | 78.7 ± 2.3 | 100.0 ± 0.0 | 96.0 ± 6.9 | 91.5 |
| Text (Caption) | SD 1.5 | 96.0 ± 4.0 | 88.0 ± 6.9 | 80.0 ± 8.0 | 100.0 ± 0.0 | 98.7 ± 2.3 | 92.5 |
| CoOp | SD 1.5 | 96.0 ± 4.0 | 89.3 ± 2.3 | 81.3 ± 6.1 | 100.0 ± 0.0 | 96.0 ± 6.9 | 92.5 |
| TADP | SD 1.5 | 96.0 ± 4.0 | 90.7 ± 4.6 | 80.0 ± 10.6 | 100.0 ± 0.0 | 96.0 ± 4.0 | 93.1 |
| ORCA (Ours) | SD 1.5 | 98.7 ± 2.3 | 90.7 ± 4.6 | 88.0 ± 6.9 | 100.0 ± 0.0 | 98.7 ± 2.3 | 95.2 |
Adroit
| Methods | Backbone | Pen | Relocate | Mean |
|---|---|---|---|---|
| CLIP | ViT-L/16 | 58.7 ± 2.3 | 44.0 ± 4.0 | 51.4 |
| VC-1 | ViT-L/16 | 65.3 ± 16.7 | 29.3 ± 8.3 | 47.3 |
| SCR† | SD 1.5 | 84.0 ± 4.0 | 32.0 ± 4.0 | 58.0 |
| Text (Simple) | SD 1.5 | 80.0 ± 6.9 | 34.7 ± 6.1 | 57.3 |
| Text (Caption) | SD 1.5 | 80.0 ± 4.0 | 34.7 ± 4.6 | 57.3 |
| CoOp | SD 1.5 | 82.7 ± 6.1 | 33.3 ± 6.1 | 58.0 |
| TADP | SD 1.5 | 81.3 ± 6.1 | 33.3 ± 8.3 | 57.3 |
| ORCA (Ours) | SD 1.5 | 86.7 ± 2.3 | 44.0 ± 4.0 | 65.3 |
Analysis
Ablation studies
| Components | DeepMind Control | ||||||
|---|---|---|---|---|---|---|---|
| pt | pv | Walker-stand | Walker-walk | Reacher-easy | Cheetah-run | Finger-spin | Mean |
| 85.5 ± 2.6 | 64.3 ± 3.5 | 81.8 ± 1.7 | 43.4 ± 4.4 | 66.6 ± 2.7 | 68.3 | ||
| ✓ | 83.6 ± 3.2 | 71.4 ± 3.5 | 86.7 ± 6.6 | 38.9 ± 10.1 | 68.2 ± 1.2 | 69.8 | |
| ✓ | 85.9 ± 2.7 | 71.1 ± 2.3 | 87.3 ± 5.5 | 42.0 ± 10.4 | 66.1 ± 1.0 | 70.5 | |
| ✓ | ✓ | 89.1 ± 2.3 | 76.9 ± 4.0 | 87.6 ± 2.9 | 50.0 ± 8.4 | 68.0 ± 1.0 | 74.3 |
The component analysis reveals that task prompts and visual prompts may have inconsistent performance when used individually, as different tasks benefit from each to varying degrees. However, combining both prompts yields consistent performance gains across all tasks, demonstrating that they are complementary.
Layer selection
| Layer | Walker-stand | Walker-walk | Reacher-easy | Cheetah-run | Finger-spin | Mean |
|---|---|---|---|---|---|---|
| down_1 | 86.3 ± 2.1 | 65.5 ± 1.1 | 82.1 ± 3.7 | 40.8 ± 1.1 | 67.6 ± 0.3 | 68.4 |
| down_2 | 89.3 ± 1.2 | 68.3 ± 2.7 | 70.0 ± 18.8 | 31.2 ± 2.6 | 67.0 ± 1.0 | 65.1 |
| down_3 | 86.2 ± 4.3 | 73.3 ± 3.9 | 75.3 ± 8.1 | 36.0 ± 4.8 | 67.0 ± 0.5 | 67.5 |
| mid | 88.3 ± 4.9 | 70.4 ± 1.3 | 62.3 ± 1.1 | 35.0 ± 4.7 | 67.2 ± 0.6 | 64.6 |
| up_0 | 82.8 ± 2.6 | 71.7 ± 5.9 | 45.3 ± 4.0 | 28.5 ± 1.8 | 67.2 ± 0.6 | 59.0 |
| up_1 | 79.5 ± 4.5 | 60.3 ± 16.1 | 55.9 ± 5.2 | 39.9 ± 7.0 | 66.4 ± 0.4 | 60.4 |
| up_2 | 70.4 ± 4.5 | 39.1 ± 3.3 | 41.0 ± 7.0 | 30.9 ± 3.1 | 67.7 ± 1.0 | 49.7 |
| down_1-3, mid | 89.1 ± 1.8 | 76.9 ± 4.0 | 87.6 ± 2.9 | 50.0 ± 8.4 | 68.0 ± 1.0 | 74.3 |
The layer-wise evaluation shows that features from the early downsampling and middle blocks of the diffusion U-Net consistently outperform those from the later upsampling layers. Therefore, we concatenate these top-performing early layers (down_1-3, mid), which achieves the best overall results and aligns with prior findings that early-layer representations are more effective for robotic control.
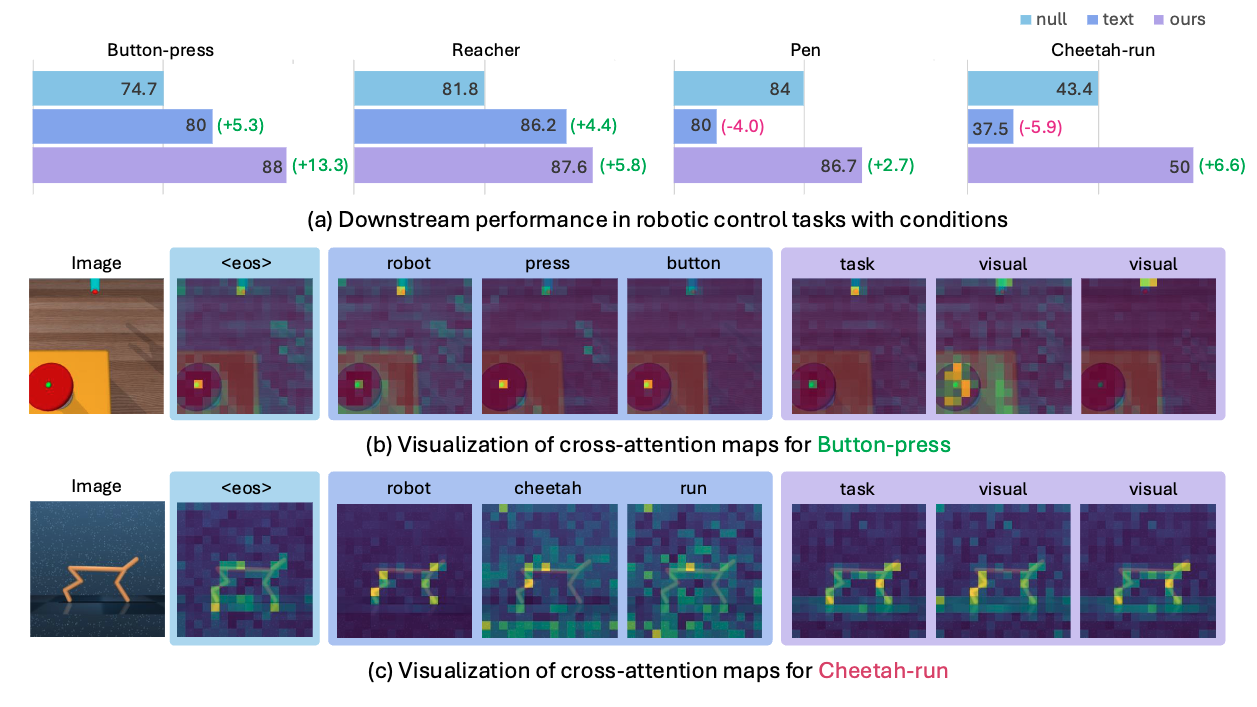
Visualization of task and visual prompts

The cross-attention visualizations for the "Relocate" task show the task prompt consistently focuses on goal-relevant objects like the robot hand and target sphere. In contrast, the visual prompts behave dynamically, with one tracking the hand while the other learns to capture task-relevant motion by shifting its attention from the table to the hand as it moves.
Qualitative Results
Citation
If you use this work or find it helpful, please consider citing:
@misc{shin2025exploringconditionsdiffusionmodels,
title={Exploring Conditions for Diffusion models in Robotic Control},
author={Heeseong Shin and Byeongho Heo and Dongyoon Han and Seungryong Kim and Taekyung Kim},
year={2025},
eprint={2510.15510},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.15510},
}